| 範例 |
| 正規表示式範例 |
| 數字範圍 |
| 浮點數 |
| 電子郵件地址 |
| IP 位址 |
| 有效的日期 |
| 數字日期轉為文字 |
| 信用卡號碼 |
| 比對完整行 |
| 刪除重複行 |
| 程式設計 |
| 兩個相近的字詞 |
| 陷阱 |
| 災難性的回溯 |
| 過多的重複 |
| 拒絕服務 |
| 讓所有內容變成可選 |
| 重複的擷取群組 |
| 混合 Unicode 和 8 位元 |
| 本網站更多內容 |
| 簡介 |
| 正規表示式快速入門 |
| 正規表示式教學 |
| 替換字串教學 |
| 應用程式和語言 |
| 正規表示式範例 |
| 正規表示式參考 |
| 替換字串參考 |
| 書籍評論 |
| 可列印 PDF |
| 關於本網站 |
| RSS 饋送和部落格 |

失控的正規表示式:災難性的回溯
考慮正規表示式 (x+x+)+y。在您驚聲尖叫並說這個人為範例應該寫成 xx+y 或 x{2,}y 以完全比對相同內容,而不需要那些可怕的巢狀量詞:假設每個「x」都代表更複雜的內容,某些字串會同時被「x」比對到。請參閱下方 HTML 檔案區段以取得實際範例。
讓我們看看將這個正規表示式套用至 xxxxxxxxxxy 時會發生什麼事。第一個 x+ 將比對到所有 10 個 x 字元。第二個 x+ 失敗。第一個 x+ 接著回溯至 9 個比對,而第二個則擷取剩餘的 x。群組現在已比對一次。群組重複,但在第一個 x+ 失敗。由於一次重複就已足夠,因此群組比對成功。y 比對到 y,並找到整體比對。正規表示式宣告功能正常,程式碼運送至客戶,而他的電腦爆炸了。幾乎如此。
當主旨字串中缺少 y 時,上述正規表示式會變得醜陋。當 y 失敗時,正規表示式引擎會回溯。群組有一個可以回溯的迭代。第二個 x+ 僅匹配一個 x,因此它無法回溯。但第一個 x+ 可以放棄一個 x。第二個 x+ 會立即匹配 xx。群組再次有一個迭代,失敗下一個,而 y 失敗。再次回溯,第二個 x+ 現在有一個回溯位置,將其縮小為匹配 x。群組嘗試第二次迭代。第一個 x+ 匹配,但第二個卡在字串結尾。再次回溯,群組第一次迭代中的第一個 x+ 將其縮小為 7 個字元。第二個 x+ 匹配 xxx。失敗 y,第二個 x+ 縮小為 xx,然後 x。現在,群組可以匹配第二次迭代,每個 x+ 有 x。但這個 (7,1),(1,1) 組合也失敗了。因此,它會轉到 (6,4),然後 (6,2)(1,1),然後 (6,1),(2,1),然後 (6,1),(1,2),然後我想你開始掌握要領了。
如果你在 RegexBuddy 的偵錯程式 中對 10x 字串嘗試這個正規表示式,它需要 2558 個步驟才能找出最後一個 y 遺失。對於 11x 字串,它需要 5118 個步驟。對於 12,它需要 10238 個步驟。顯然,我們這裡有 O(2^n) 的指數複雜度。在 19x 時,偵錯程式會退出,因為它不會顯示超過一百萬個步驟。
RegexBuddy 很寬容,因為它會偵測到它正在繞圈圈,並中止匹配嘗試。其他正規表示式引擎(例如 .NET)會一直執行下去,而其他引擎會因堆疊溢位而崩潰(例如 Perl,在 5.10 版之前)。在 Windows 上,堆疊溢位特別令人討厭,因為它們往往會讓你的應用程式消失,而沒有任何痕跡或解釋。如果你執行允許使用者提供自己的正規表示式的網路服務,請務必小心。正規表示式經驗不足的人在提出指數複雜的正規表示式方面具有驚人的技巧。
所有格量詞和原子群組救援
在上述範例中,最明智的做法顯然是將其改寫為 xx+y,如此一來便能完全消除巢狀量詞。巢狀量詞是指在本身重複或交替的群組內部重複或交替的代幣。這些幾乎總是會導致災難性的回溯。唯一不會造成回溯的情況是群組內部每個選項的開頭都不是可選的,且與所有其他選項的開頭互斥,以及與其後面的代幣互斥(在群組內部其選項內)。例如 (a+b+|c+d+)+y 是安全的。如果任何項目失敗,正規表示式引擎會回溯整個正規表示式,但會線性執行。原因在於所有代幣都互斥。沒有任何代幣可以比對任何其他代幣比對的字元。因此,在每個回溯位置的比對嘗試都會失敗,導致正規表示式引擎線性回溯。如果您在 aaaabbbbccccdddd 上測試這個正規表示式,RegexBuddy 只需要 13 個步驟就能找出結果,而不是數百萬個步驟。
然而,要改寫正規表示式讓所有項目都互斥並非總是可行或容易。因此,我們需要一種方法來告訴正規表示式引擎不要回溯。當我們取得所有 x 時,不需要回溯。在 x+ 比對的任何項目中都不可能會有 y。使用 所有格量詞,我們的正規表示式會變成 (x+x+)++y。這會在僅僅 7 個步驟中讓 21x 字串失敗。其中 6 個步驟用於比對所有 x,1 個步驟用於找出 y 失敗。幾乎沒有進行回溯。使用 原子群組,正規表示式會變成 (?>(x+x+)+)y,結果完全相同。
實際範例:比對 CSV 記錄
以下是我曾經處理過的一個技術支援案例的實際範例。客戶嘗試在一個逗號分隔文字檔案中找出第 12 個項目以 P 開頭的行。他使用看似無害的正規表示式 ^(.*?,){11}P。
乍看之下,這個正規表示式似乎可以順利完成任務。懶惰點和逗號比對單一逗號分隔欄位,而 {11} 會略過前 11 個欄位。最後,P 會檢查第 12 個欄位是否確實以 P 開頭。事實上,當第 12 個欄位確實以 P 開頭時,就會發生這種情況。
當第 12 個欄位不以 P 開頭時,問題就會浮現。假設字串為 1,2,3,4,5,6,7,8,9,10,11,12,13。在那個時候,正規表示式引擎會回溯。它會回溯到 ^(.*?,){11} 已消耗 1,2,3,4,5,6,7,8,9,10,11 的位置,放棄逗號的最後一個比對。下一個代幣再次為點。點比對逗號。點比對逗號!然而,逗號不比對第 12 個欄位的 1,因此點會持續到 .*?, 的第 11 次反覆已消耗 11,12,。你已經可以看到問題的根源:正規表示式的一部分(點)比對欄位的內容也會比對分隔符(逗號)。由於重複兩次({11} 內的星號),這會導致大量的回溯。
正規表示式引擎現在會檢查第 13 個欄位是否以 P 開頭。它沒有。由於第 13 個欄位後沒有逗號,正規表示式引擎無法再比對 .*?, 的第 11 次反覆。但它不會就此放棄。它會回溯到第 10 次反覆,將第 10 次反覆的比對擴充為 10,11,。由於仍然沒有 P,因此第 10 次反覆擴充為 10,11,12,。再次到達字串的結尾,同樣的故事從第 9 次反覆開始,隨後將其擴充為 9,10,、9,10,11,、9,10,11,12,。但在每次擴充之間,都有更多可能性需要嘗試。當第 9 次反覆消耗 9,10, 時,第 10 次反覆可以比對 11, 也可以比對 11,12,。引擎持續失敗,回溯到第 8 次反覆,再次嘗試第 9、10 和 11 次反覆的所有可能組合。
你應該了解了:正規表示式引擎將嘗試第 12 個欄位不以 P 開頭的每一行的組合數量非常龐大。如果你對一個大型 CSV 檔案執行這個正規表示式,而大多數列的第 12 個欄位開頭都沒有 P,這將會花費很長的時間。
防止災難性的回溯
解決方案很簡單。在巢狀重複運算子時,務必確保只有一個方式可以匹配相同的匹配。如果重複內部迴圈 4 次和外部迴圈 7 次會產生與重複內部迴圈 6 次和外部迴圈 2 次相同的整體匹配,則可以確定正規表示式引擎會嘗試所有這些組合。
在我們的範例中,解決方案是更精確地說明我們要匹配的內容。我們要匹配 11 個以逗號分隔的欄位。欄位不得包含逗號。因此,正規表示式變為:^([^,\r\n]*,){11}P。如果找不到 P,引擎仍會回溯。但它只會回溯 11 次,而且每次[^,\r\n]都無法擴展到逗號以外,迫使正規表示式引擎立即回到 11 次反覆運算中的前一次,而不嘗試進一步的選項。
使用 RegexBuddy 查看差異
如果您使用 RegexBuddy 的偵錯程式 嘗試此範例,您會看到原始正規表示式 ^(.*?,){11}P 需要 25,593 個步驟才能得出結論,正規表示式無法匹配 1,2,3,4,5,6,7,8,9,10,11,12。如果字串是 1,2,3,4,5,6,7,8,9,10,11,12,13,僅多 3 個字元,步驟數就會加倍到 52,149。不難想像,以這種指數級的速度,嘗試在包含長行的巨集中執行這個正規表示式,很容易就會花上永遠的時間。
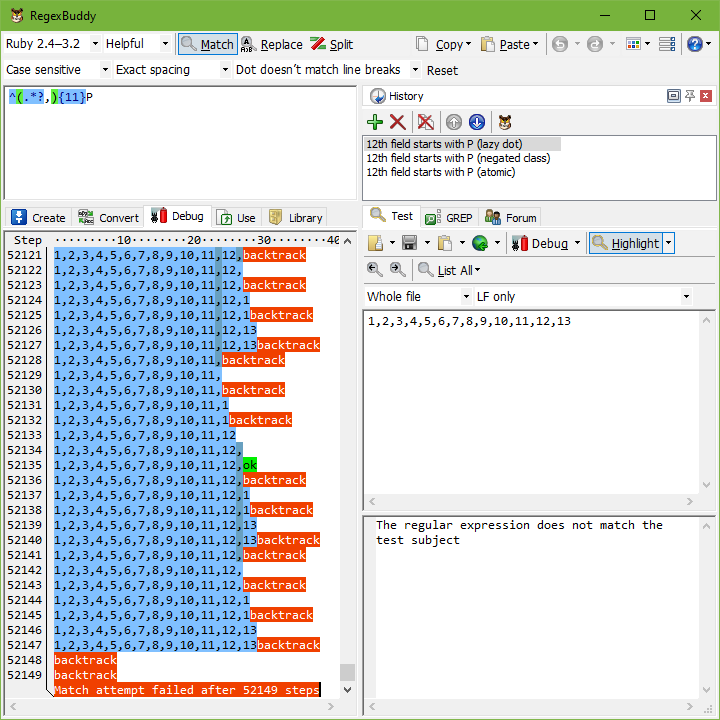
我們改良過的正規表示式 ^([^,\r\n]*,){11}P,然而,只要 52 個步驟就會失敗,無論主旨字串有 12 個數字、13 個數字、16 個數字或十億個數字。雖然原始正規表示式的複雜度為指數級,但改良過正規表示式的複雜度與第 11 個欄位之後的任何內容相比都是常數。原因是當正規表示式發現第 12 個欄位不是以 P 開頭時,幾乎會立即失敗。它會回溯群組的 11 次反覆運算,而不會再次擴充。
改良過正規表示式的複雜度與前 11 個欄位的長度成線性關係。在我們的範例中,需要 24 個步驟來比對 11 個欄位。只要 1 個步驟就能發現無法比對 P。然後需要另外 27 個步驟來回溯兩個量詞的所有反覆運算。那是我們所能做的最好了,因為引擎確實必須掃描前 11 個欄位的全部字元,才能找出第 12 個欄位從何處開始。我們改良過的正規表示式是一個完美的解決方案。
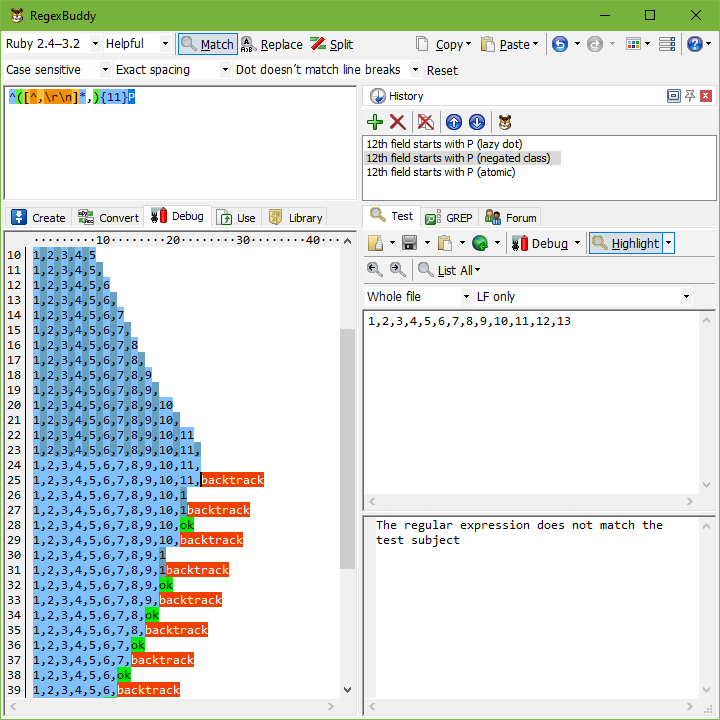
使用原子群組的替代解決方案
在上述範例中,我們可以透過更精確地指定我們要的內容,輕鬆地將回溯量減少到非常低的程度。但這種方式並非總是可行。在這種情況下,您應該使用原子群組來防止正規表示式引擎進行回溯。
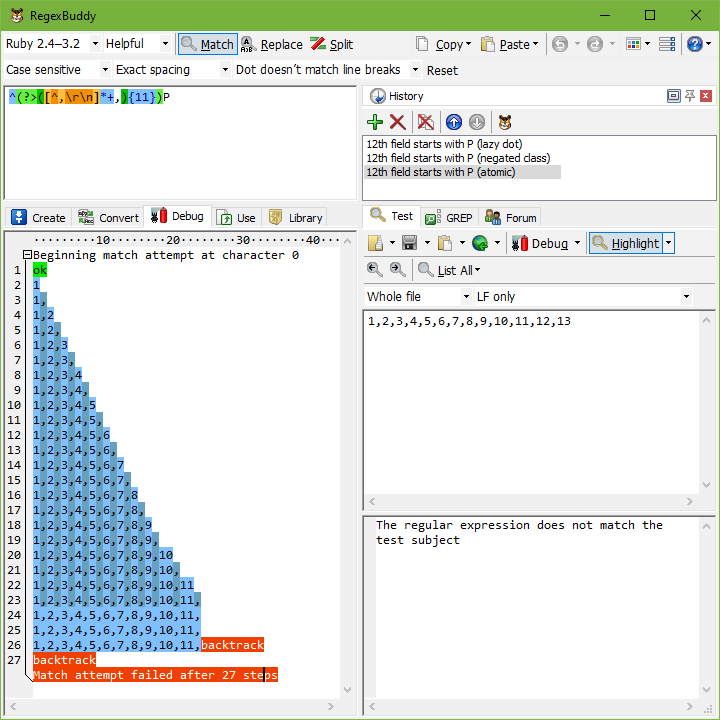
使用 原子群組,上述正規表示式會變成 ^(?>(.*?,){11})P。一旦正規表示式引擎離開群組,(?>) 之間的所有內容都會被正規表示式引擎視為單一記號。由於整個群組只是一個記號,因此一旦正規表示式引擎找到群組的比對,就不會進行回溯。如果需要回溯,引擎必須回溯到群組之前的正規表示式記號(在我們的範例中為插入符號)。如果群組之前沒有記號,正規表示式必須在字串中的下一個位置重試整個正規表示式。
讓我們看看 ^(?>(.*?,){11})P 如何套用於 1,2,3,4,5,6,7,8,9,10,11,12,13。插入符號會與字串開頭相符,而引擎會進入原子群組。星號是延遲的,因此點號最初會被跳過。但逗號與 1 不相符,因此引擎會回溯至點號。沒錯:在此允許回溯。星號並非獨佔,且並未立即被原子群組包圍。也就是說,正規表示式引擎並未跨越原子群組的右括號。點號與 1 相符,逗號也相符。 {11} 會導致進一步重複,直到原子群組與 1,2,3,4,5,6,7,8,9,10,11, 相符。
現在,引擎會離開原子群組。由於群組是原子的,因此所有回溯資訊都會被捨棄,而群組現在被視為單一記號。引擎現在會嘗試將 P 與第 12 個欄位中的 1 相符。這會失敗。
到目前為止,所有事情都與原始的麻煩正規表示式一樣。現在出現了差異。 P 無法相符,因此引擎會回溯。但原子群組讓它忘記所有回溯位置。在字串開頭的相符嘗試會立即失敗。
這就是原子群組和獨佔量詞的用途:透過不允許回溯來提升效率。針對我們手邊的問題,最有效的正規表示式會是 ^(?>((?>[^,\r\n]*),){11})P,因為星號的獨佔貪婪重複比延遲延遲點號還要快。如果可以使用獨佔量詞,你可以透過撰寫 ^(?>([^,\r\n]*+,){11})P 來減少雜訊。
如果你在 RegexBuddy 的偵錯程式中測試最終解決方案,你會看到它需要相同的 24 個步驟來與 11 個欄位相符。然後它會執行 1 個步驟來退出原子群組並捨棄所有回溯資訊。發現 P 無法相符仍然需要 1 個步驟。但由於原子群組,回溯所有資訊只需要 1 個步驟。
快速相符完整的 HTML 檔案
另一個會發生災難性回溯的常見情況是,當嘗試比對「某個東西」後接「任何東西」後接「另一個東西」後接「任何東西」,其中使用惰性點號 .*?。越多的「任何東西」,回溯就越多。有時候,惰性點號只是惰性程式設計師的徵兆。 ".*?" 不適合用來比對雙引號字串,因為你並不想允許引號之間出現任何東西。字串不能有(未跳脫)嵌入式引號,所以 "[^"\r\n]*" 比較適合,而且在與較大的正規表示式結合時不會導致災難性回溯。然而,有時候「任何東西」真的就是這樣。問題在於「另一個東西」也符合「任何東西」的資格,讓我們遇到真正的 x+x+ 情況。
假設你想要使用正規表示式來比對完整的 HTML 檔案,並從檔案中擷取基本部分。如果你知道 HTML 檔案的結構,撰寫正規表示式 <html>.*?<head>.*?<title>.*?</title>.*?</head>.*?<body[^>]*>.*?</body>.*?</html> 非常容易。在開啟「點號比對換行」或「單行」比對模式 的情況下,它會在有效的 HTML 檔案上正常運作。
不幸的是,此正規表示式在缺少某些標籤的 HTML 檔案中無法順利運作。最糟的情況是檔案結尾缺少 </html> 標籤。當 </html> 無法配對時,正規表示式引擎會回溯,放棄 </body>.*? 的配對。然後,它會進一步擴充 </body> 前面的惰性點,尋找 HTML 檔案中的第二個關閉 </body> 標籤。當這項動作失敗時,引擎會放棄 <body[^>]*>.*?,並開始尋找第二個開啟 <body[^>]*> 標籤,一直到檔案結尾。由於這項動作也會失敗,因此引擎會繼續尋找第二個關閉 head 標籤、第二個關閉 title 標籤等,一直到檔案結尾。
如果您在 RegexBuddy 的偵錯程式 中執行此正規表示式,輸出結果看起來會像鋸齒狀。正規表示式會配對整個檔案,後退一點,再次配對整個檔案,再後退一點,再後退一點,再次配對所有內容等,直到 7 個 .*? 權杖中的每個權杖都到達檔案結尾。結果是此正規表示式的最差情況複雜度為 N^7。如果您透過在結尾附加文字來將缺少 <html> 標籤的 HTML 檔案長度加倍,正規表示式將需要花費 128 倍 (2^7) 的時間才能找出 HTML 檔案無效。這不像我們第一個範例的 2^N 複雜度那麼慘烈,但對於較大的無效檔案,效能會非常不可接受。
在這種情況下,我們知道正規表示式中的每個文字區塊 (HTML 標籤,用作分隔符號) 在有效的 HTML 檔案中只會出現一次。這使得將每個惰性點 (分隔內容) 封裝在原子群組中變得非常容易。
<html>(?>.*?<head>)(?>.*?<title>)(?>.*?</title>)(?>.*?</head>)(?>.*?<body[^>]*>)
(?>.*?</body>).*?</html> 將在與原始正規表示式相同的步驟數中比對有效的 HTML 檔案。優點是,它會在無效 HTML 檔案中幾乎與比對有效檔案一樣快地失敗。當 </html> 無法比對時,正規表示式引擎會回溯,放棄比對最後一個惰性點。但是,之後就沒有什麼可以回溯的了。由於所有惰性點都在原子群組中,因此正規表示式引擎已捨棄其回溯位置。群組的作用是「不要進一步擴充」的障礙。正規表示式引擎被迫立即宣告失敗。
您一定注意到每個原子群組在惰性點之後還包含一個 HTML 標籤。這一點至關重要。我們允許惰性點回溯,直到找到其匹配的 HTML 標籤。例如,當 .*?</body> 正在處理 Last paragraph</p></body> 時,</ 正規表示式代幣將匹配 </ 中的 </p>。但是,b 將無法匹配 p。在那個時候,正規表示式引擎將回溯並擴充惰性點以包含 </p>。由於正規表示式引擎尚未離開原子群組,因此它可以在群組內自由回溯。一旦 </body> 匹配,正規表示式引擎離開原子群組,它會捨棄惰性點的回溯位置。然後它將無法再擴充。
基本上,我們所做的是將一個重複的正規表示式代幣(惰性點用於匹配 HTML 內容)與其後面的非重複正規表示式代幣(文字 HTML 標籤)繫結。由於任何內容,包括 HTML 標籤,都可能出現在我們正規表示式中的 HTML 標籤之間,因此我們無法使用否定字元類別來代替惰性點,以防止分隔 HTML 標籤被匹配為 HTML 內容。但是,我們可以透過將每個惰性點與其後面的 HTML 標籤組合成一個原子群組來達成相同的結果。一旦 HTML 標籤匹配,惰性點的匹配就會被鎖定。這可確保惰性點永遠不會匹配應該由正規表示式中的文字 HTML 標籤匹配的 HTML 標籤。
| 快速入門 | 教學 | 工具和語言 | 範例 | 參考 | 書籍評論 |
| 正規表示式範例 | 數字範圍 | 浮點數 | 電子郵件地址 | IP 位址 | 有效日期 | 數字日期轉文字 | 信用卡號碼 | 匹配完整行 | 刪除重複行 | 程式設計 | 兩個相近的字 |
| 災難性回溯 | 重複次數太多 | 拒絕服務 | 讓所有內容都變成可選 | 重複擷取群組 | 混合 Unicode 和 8 位元 |
頁面網址:https://regular-expressions.dev.org.tw/catastrophic.html
頁面最後更新時間:2021 年 8 月 15 日
網站最後更新時間:2024 年 3 月 15 日
版權所有 © 2003-2024 Jan Goyvaerts。保留所有權利。